http-https
HTTP HTTPS
http&https释义
HTTP(Hyper Text Transfer Protocol)超文本传输协议,是一种建立在TCP上的无状态连接。用来在计算机世界里传输文字,图片,音频,视频等超文本数据的约定和规范。
HTTPS(Hyper Text Transfer Protocol Secure)安全的超文本传输协议,它是基于HTTP+TLS/SSL实现的,可以说是披上了一层TLS/SSL的HTTP协议。
TCP/IP网络模型
常见的TCP/IP网络模型为5层模型:
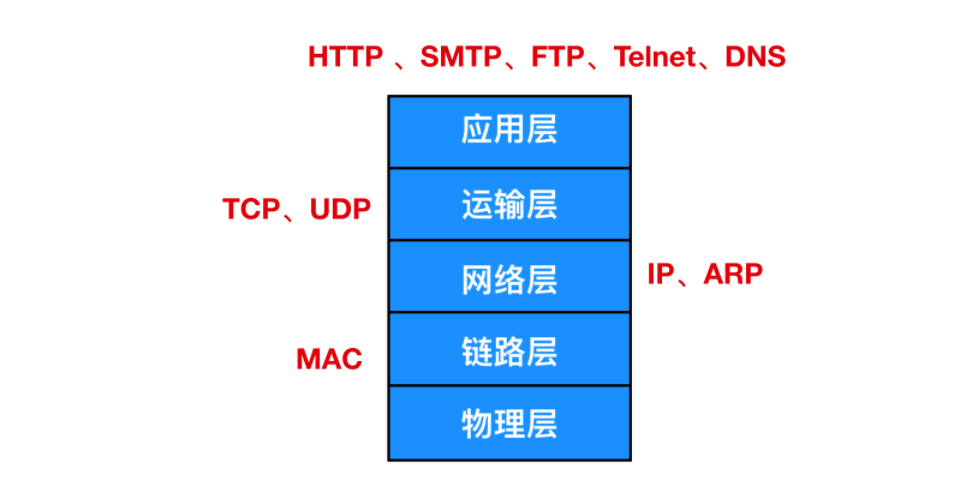
也可以分为四层,即把数据链路层和物理层统一表示为网络接口层。
还有一种是OSI七层网络模型,它在五层基础上,在应用层之下,运输层之上添加了:表示层和会话层。
http与https区别
由以上可知,https是披了一层SSL的http。如下所示,它是在应用层 与传输层 之间添加了一层SSL(安全套接字层)。
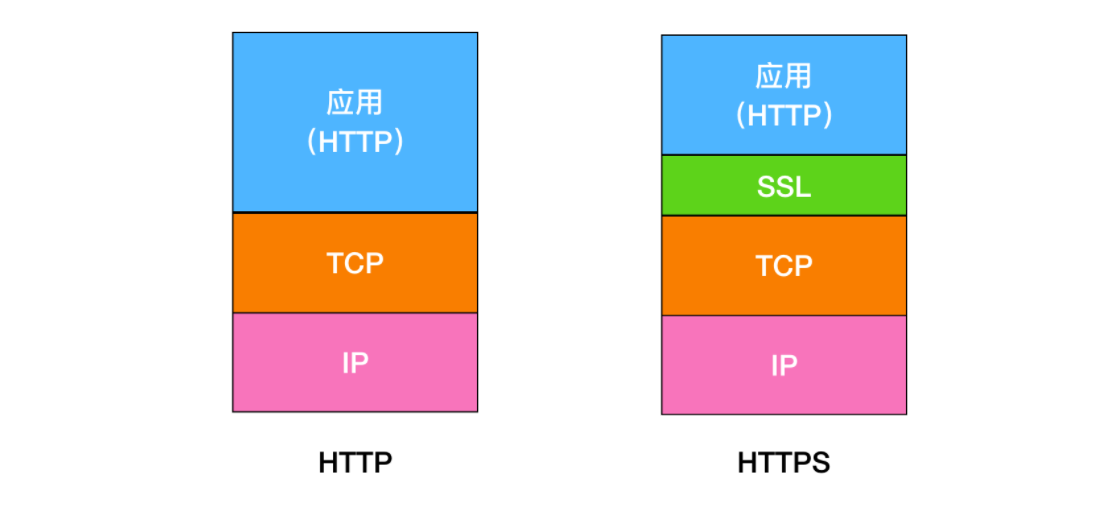
对比
| HTTP | HTTPS | |
|---|---|---|
| 协议 | http:// | Https:// |
| 端口 | 80 | 443 |
| 安全 | 未经安全加密的协议 | 通过密钥交换算法-签名算法-对称加密算法-摘要算法进行加密 |
| 证书 | 不需要证书 | 需要CA机构颁发的SSL证书 |
| OSI位置 | 应用层 | 其安全传输机制工作在传输层 |
HTTPS请求过程
- 客户端向服务器发起HTTPS请求,连接到服务器的443端口
- 服务器端有一个密钥对,即公钥和私钥,是用来进行非对称加密使用的,服务器端保存着私钥,不能将其泄露,公钥可以发送给任何人。
- 服务器将自己的公钥发送给客户端。
- 客户端收到服务器端的公钥之后,会对公钥进行检查,验证其合法性,如果发现发现公钥有问题,那么HTTPS传输就无法继续。严格的说,这里应该是验证服务器发送的数字证书的合法性,关于客户端如何验证数字证书的合法性,下文会进行说明。如果公钥合格,那么客户端会生成一个随机值,这个随机值就是用于进行对称加密的密钥,我们将该密钥称之为client key,即客户端密钥,这样在概念上和服务器端的密钥容易进行区分。然后用服务器的公钥对客户端密钥进行非对称加密,这样客户端密钥就变成密文了,至此,HTTPS中的第一次HTTP请求结束。
- 客户端会发起HTTPS中的第二个HTTP请求,将加密之后的客户端密钥发送给服务器。
- 服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后的明文就是客户端密钥,然后用客户端密钥对数据进行对称加密,这样数据就变成了密文。
- 然后服务器将加密后的密文发送给客户端。
- 客户端收到服务器发送来的密文,用客户端密钥对其进行对称解密,得到服务器发送的数据。这样HTTPS中的第二个HTTP请求结束,整个HTTPS传输完成。
一次完整的HTTP请求
- 建立TCP连接
- 浏览器向服务器发送请求行(例如:GET /example/a.html HTTP/1.1)
- 浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
- 浏览器发送请求头
- 服务器应答,返回状态行(例如:HTTP/1.1 200 OK )
- 服务器发送应答头
- 服务器向浏览器发送数据
- 服务器关闭TCP连接
Connection:keep-alive: TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
TCP UDP
TCP与UDP都工作在计算机网络模型中的传输层,他们负责传输应用层产生的数据。
TCP UDP释义
TCP :(Transimission Control Protocol),传输控制协议,它通过三次握手来建立TCP连接,连接建立完成即可传输数据,待数据传输完成它通过四次挥手断开连接。
UDP:(User Datagram Protocol),用户数据报协议,它不需要握手操作,从而加快了通信速度,允许网络上其他主机在同意接收数据前进行数据传输。
TCP与UDP区别
| TCP | UDP |
|---|---|
| 面向连接 | 无连接 |
| 发送数据之前先建立连接 | 无需建立连接即可发送数据 |
| 按照特定顺序重新排列数据包 | 数据包没有特定顺序,所有数据包相互独立 |
| 传输速度较慢 | 传输速度较快 |
| 头部字节由20字节 | 头部字节只有8字节 |
| 重量级的,需要三次握手 | 轻量级的,啥都不需要 |
| 会进行错误校验,错误恢复 | 会进行错误校验,但会丢弃错误的数据包 |
| 有确认发送,确认重传机制 | 无确认发送 |
| 可靠,保证数据发送到服务器 | 不可靠 |
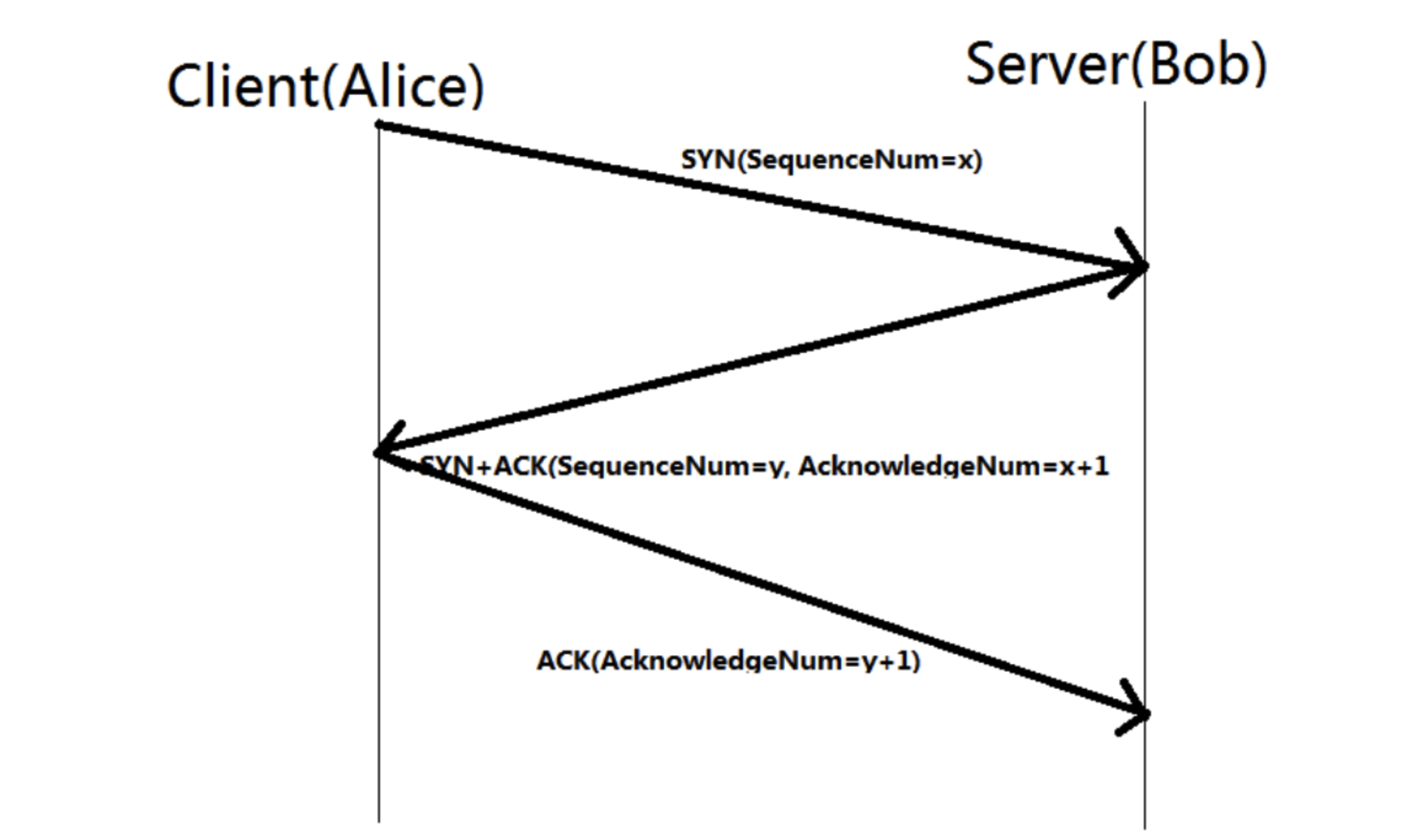
TCP三次握手
SYN:它的全称是
Synchronize Sequence Numbers,同步序列编号。是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立 TCP 连接时,首先会发送的一个信号。客户端在接受到 SYN 消息时,就会在自己的段内生成一个随机值 X。SYN-ACK:服务器收到 SYN 后,打开客户端连接,发送一个 SYN-ACK 作为答复。确认号设置为比接收到的序列号多一个,即 X + 1,服务器为数据包选择的序列号是另一个随机数 Y。
ACK:
Acknowledge character, 确认字符,表示发来的数据已确认接收无误。最后,客户端将 ACK 发送给服务器。序列号被设置为所接收的确认值即 Y + 1。
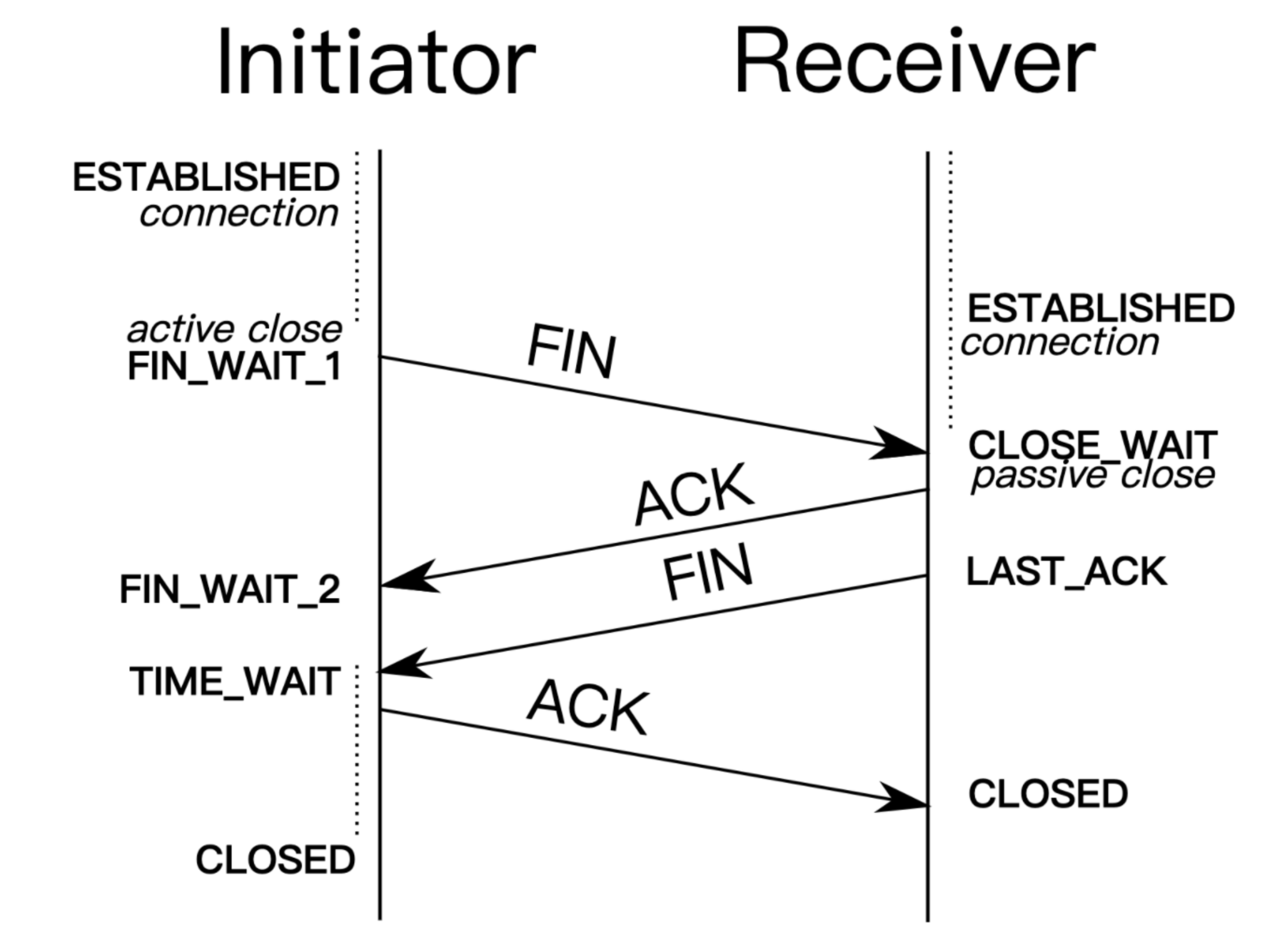
TCP四次挥手
首先,客户端应用程序决定要终止连接(这里服务端也可以选择断开连接)。这会使客户端将 FIN 发送到服务器,并进入
FIN_WAIT_1状态。当客户端处于 FIN_WAIT_1 状态时,它会等待来自服务器的 ACK 响应。当服务器收到 FIN 消息时,服务器会立刻向客户端发送 ACK 确认消息。
当客户端收到服务器发送的 ACK 响应后,客户端就进入
FIN_WAIT_2状态,然后等待来自服务器的FIN消息服务器发送 ACK 确认消息后,一段时间(可以进行关闭后)会发送 FIN 消息给客户端,告知客户端可以进行关闭。
当客户端收到从服务端发送的 FIN 消息时,客户端就会由 FIN_WAIT_2 状态变为
TIME_WAIT状态。处于 TIME_WAIT 状态的客户端允许重新发送 ACK 到服务器为了防止信息丢失。客户端在 TIME_WAIT 状态下花费的时间取决于它的实现,在等待一段时间后,连接关闭,客户端上所有的资源(包括端口号和缓冲区数据)都被释放。
HTTP1.0 / 1.1 /1.2
HTTP的基本优化
影响一个HTTP网络请求的因素主要有两个:带宽 和 延迟。
带宽:如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
延迟:
- 浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
- DNS 查询(DNS Lookup):浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
- 建立连接(Initial connection):HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
针对DNS查询的优化,可以采用prefetch方案,如下。浏览器空闲时先将这些域名经过DNS查询转换为对应的IP地址,真正请求资源时就避免DNS查询所浪费的时间。
1 | <meta http-equiv='x-dns-prefetch-control' content='on'> |
HTTP1.0
HTTP 1.0 是在 1996 年引入的,从那时开始,它的普及率就达到了惊人的效果。
- HTTP 1.0 仅仅提供了最基本的认证,这时候用户名和密码还未经加密,因此很容易收到窥探。
- HTTP 1.0 被设计用来使用短链接,即每次发送数据都会经过 TCP 的三次握手和四次挥手,效率比较低。
- HTTP 1.0 只使用 header 中的 If-Modified-Since 和 Expires 作为缓存失效的标准。
- HTTP 1.0 不支持断点续传,也就是说,每次都会传送全部的页面和数据。
- HTTP 1.0 认为每台计算机只能绑定一个 IP,所以请求消息中的 URL 并没有传递主机名(hostname)。
HTTP1.1
HTTP 1.1 是 HTTP 1.0 开发三年后出现的,也就是 1999 年,它做出了以下方面的变化
- HTTP 1.1 使用了摘要算法来进行身份验证
- HTTP 1.1 默认使用长连接,长连接就是只需一次建立就可以传输多次数据,传输完成后,只需要一次切断连接即可。长连接的连接时长可以通过请求头中的
keep-alive来设置 - HTTP 1.1 中新增加了 E-tag,If-Unmodified-Since, If-Match, If-None-Match 等缓存控制标头来控制缓存失效。
- HTTP 1.1 支持断点续传,通过使用请求头中的
Range来实现。 - HTTP 1.1 使用了虚拟网络,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
HTTP2.0
- 头部压缩,由于 HTTP 1.1 经常会出现 User-Agent、Cookie、Accept、Server、Range 等字段可能会占用几百甚至几千字节,而 Body 却经常只有几十字节,所以导致头部偏重。HTTP 2.0 使用
HPACK算法进行压缩。 - 二进制格式,HTTP 2.0 使用了更加靠近 TCP/IP 的二进制格式,而抛弃了 ASCII 码,提升了解析效率
- 强化安全,由于安全已经成为重中之重,所以 HTTP2.0 一般都跑在 HTTPS 上。
- 多路复用,即每一个请求都是是用作连接共享。一个请求对应一个id,这样一个连接上可以有多个请求。
一个HTTP1.1和HTTP2.0协议的对比demo:https://http2.akamai.com/demo
长连接和多路复用的区别
- HTTP1.0:一次请求相应,建立一个连接,用完关闭;
- HTTP1.1(长连接):若干个请求排队串行化单线程处理,后面的请求等待前面请求返回才会执行,一旦有某请求超时,后面请求只能呗阻塞;
- HTTP2.0(多路复用):多个请求可同时在一个连接上并行执行,某个请求任务耗时严重,并不影响其他请求。
HTTP常见请求头
请求
GET(请求的方式) /newcoder/hello.html(请求的目标资源) HTTP/1.1(请求采用的协议和版本号)
Accept: /(客户端能接收的资源类型)
Accept-Language: en-us(客户端接收的语言类型)
Connection: Keep-Alive(维护客户端和服务端的连接关系)
Host: localhost:8080(连接的目标主机和端口号)
Referer: http://localhost/links.jsp(
User-Agent: Mozilla/4.0(客户端版本号的名字)
Accept-Encoding: gzip, deflate(客户端能接收的压缩数据的类型)
If-Modified-Since: Tue, 11 Jul 2017 18:23:51 GMT(缓存时间)
Cookie(客户端暂存服务端的信息)
Date: Tue, 18 Jul 12:15:02 GMT(客户端请求服务端的时间)
相应
HTTP/1.1(响应采用的协议和版本号) 200(状态码) OK(描述信息)
Location: http://www.baidu.com(
Server:apache tomcat(服务端的Web服务端名)
Content-Encoding: gzip(服务端能够发送压缩编码类型)
Content-Length: 80(服务端发送的压缩数据的长度)
Content-Language: zh-cn(服务端发送的语言类型)
Content-Type: text/html; charset=GB2312(服务端发送的类型及采用的编码方式)
Last-Modified: Tue, 18 Jul 2017 12:15:02 GMT(服务端对该资源最后修改的时间)
Refresh: 1;url=http://www.helloyoucan.com.(
Content-Disposition: attachment; filename=aaa.zip(服务端要求客户端以下载文件的方式打开该文件)
Transfer-Encoding: chunked(分块传递数据到客户端)
Set-Cookie:SS=Q0=5Lb_nQ; path=/search(服务端发送到客户端的暂存数据)
Expires: -1//3种(服务端禁止客户端缓存页面数据)
Cache-Control: no-cache(服务端禁止客户端缓存页面数据)
Pragma: no-cache(服务端禁止客户端缓存页面数据)
Connection: close(1.0)/(1.1)Keep-Alive(维护客户端和服务端的连接关系)
Date: Tue, 18 Jul 2017 12:18:03 GMT(服务端响应客户端的时间)
在浏览器输入URL地址经历的一次完整的 url 请求
- DNS域名解析;
- TCP三次握手建立连接;
- 发起HTTP请求
- 服务器响应HTTP请求,浏览器得到html代码
- 浏览器解析html代码,并请求html代码中的资源(如js、css图片等)
- 浏览器对页面进行渲染
注:
- DNS域名解析采用的是递归查询的方式,顺序是,浏览器缓存->系统缓存->Host文件->配置的DNS服务器->根域名服务器->根域名又会去找下一级,这样进行递归查找
- 如何对页面进行渲染的
- 解析html文件构成 DOM树
- 解析CSS文件构成渲染树
- 边解析,边渲染
- JS 单线程运行,会阻塞后续资源下载。JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的
URI 和 URL 的区别
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例
- URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源
- URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
- URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com
URI结构:

scheme 表示协议名,比如http, https, file等等。后面必须和://连在一起。
user:passwd@ 表示登录主机时的用户信息,不过很不安全,不推荐使用,也不常用。
host:port表示主机名和端口。
path表示请求路径,标记资源所在位置。
query表示查询参数,为key=val这种形式,多个键值对之间用&隔开。
fragment表示 URI 所定位的资源内的一个锚点,浏览器可以根据这个锚点跳转到对应的位置。
URI编码
URI 只能使用ASCII, ASCII 之外的字符是不支持显示的,而且还有一部分符号是界定符,如果不加以处理就会导致解析出错。
常见状态码
- 1**:信息性状态码
- 2**:成功状态码
- 200:OK 请求正常处理
- 204:No Content请求处理成功,但没有资源可返回
- 206:Partial Content对资源的某一部分的请求
- 3**:重定向状态码
- 301:Moved Permanently 永久重定向
- 302:Found 临时性重定向
- 304:Not Modified 缓存中读取
- 4**:客户端错误状态码
- 400:Bad Request 请求报文中存在语法错误
- 401:Unauthorized需要有通过Http认证的认证信息
- 403:Forbidden访问被拒绝
- 404:Not Found无法找到请求资源
- 5**:服务器错误状态码
- 500:Internal Server Error 服务器端在执行时发生错误
- 503:Service Unavailable 服务器处于超负载或者正在进行停机维护
- 500:Internal Server Error 服务器端在执行时发生错误